When we talk of performance in computing, we refer to the relationship between our resources and the tasks that they allows us to complete in a given period of time.
Perf- A Performance Monitoring and Analysis Tool for Linux
In a day of fierceless competition between companies, it is important that we learn how to use what we have at the best of its capacity. The waste of hardware or software resources, or the lack of ability to know how to use them more efficiently, ends up being a loss that we just can’t afford if we want to be at the top of our game.
At the same time, we must be careful to not take our resources to a limit where sustained use will yield irreparable damage.
In this article we will introduce you to a relatively new performance analysis tool and provide tips that you can use to monitor your Linux systems, including hardware and applications. This will help you to ensure that they operate so that you are capable to produce the desired results without wasting resources or your own energy.
Introducing and installing Perf in Linux
Among others, Linux provides a performance monitoring and analysis tool called conveniently perf. So what distinguishes perf from other well-known tools with which you are already familiar?
The answer is that perf provides access to the Performance Monitoring Unit in the CPU, and thus allows us to have a close look at the behavior of the hardware and its associated events.
In addition, it can also monitor software events, and create reports out of the data that is collected.
You can install perf in RPM-based distributions with:
In Debian and derivatives:
If
uname -r in the command above returns extra strings besides the actual version (3.2.0-23-generic in my case), you may have to type linux-tools-3.2.0-23 instead of using the output of uname.
It is also important to note that perf yields incomplete results when run in a guest on top of VirtualBox or VMWare as they do not allow access to hardware counters as other virtualization technologies (such as KVM or XEN) do.
Additionally, keep in mind that some perf commands may be restricted to root by default, which can be disabled (until the system is rebooted) by doing:
If you need to disable paranoid mode permanently, update the following setting in /etc/sysctl.conf file.
Subcommands
Once you have installed perf, you can refer to its man page for a list of available subcommands (you can think of subcommands as special options that open a specific window into the system). For best and more complete results, use perf either as root or through sudo.
Perf list
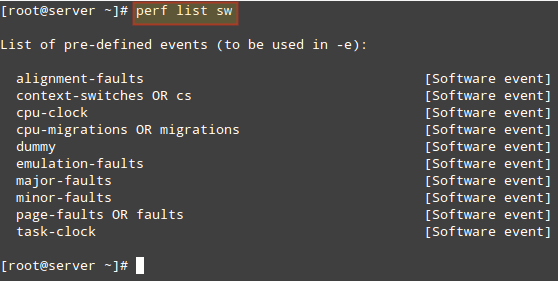
perf list (without options) returns all the symbolic event types (long list). If you want to view the list of events available in a specific category, use perf list followed by the category name ([hw|sw|cache|tracepoint|pmu|event_glob]), such as:
Display list of software pre-defined events in Linux:
List Software Pre-defined Events in Linux
Perf stat
perf stat runs a command and collects Linux performance statistics during the execution of such command. What happens in our system when we run dd?
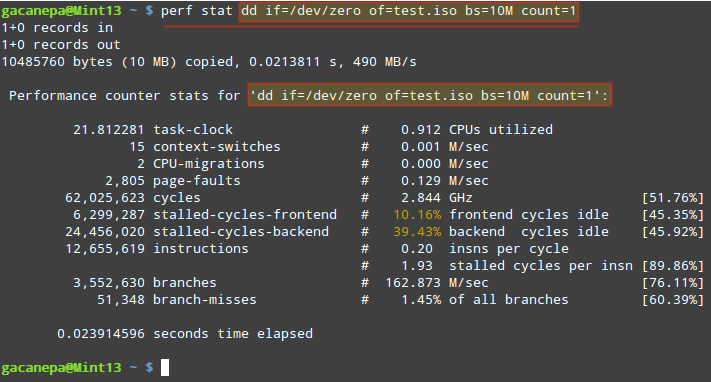
Collects Performance Statistics of Linux Command
The stats shown above indicate, among other things:
- The execution of the dd command took 21.812281 milliseconds of CPU. If we divide this number by the “seconds time elapsed” value below (23.914596 milliseconds), it yields 0.912 (CPU utilized).
- While the command was executed, 15 context-switches (also known as process switches) indicate that the CPUs were switched 15 times from one process (or thread) to another.
- 2 CPU migrations is the expected result when in a 2-core CPU the workload is distributed evenly between the number of cores.
During that time (21.812281 milliseconds), the total number of CPU cycles that were consumed was 62,025,623, which divided by 0.021812281 seconds gives 2.843 GHz. - If we divide the number of cycles by the total instructions count we get 4.9 Cycles Per Instruction, which means each instruction took almost 5 CPU cycles to complete (on average). We can blame this (at least in part) on the number of branches and branch-misses (see below), which end up wasting or misusing CPU cycles.
- As the command was executed, a total of 3,552,630 branches were encountered. This is the CPU-level representation of decision points and loops in the code. The more branches, the lower the performance. To compensate for this, all modern CPUs attempt to predict the flow the code will take. 51,348 branch-misses indicate the prediction feature was wrong 1.45% of the time.
The same principle applies to gathering stats (or in other words, profiling) while an application is running. Simply launch the desired application and after a reasonable period of time (which is up to you) close it, and perf will display the stats in the screen. By analyzing those stats you can identify potential problems.
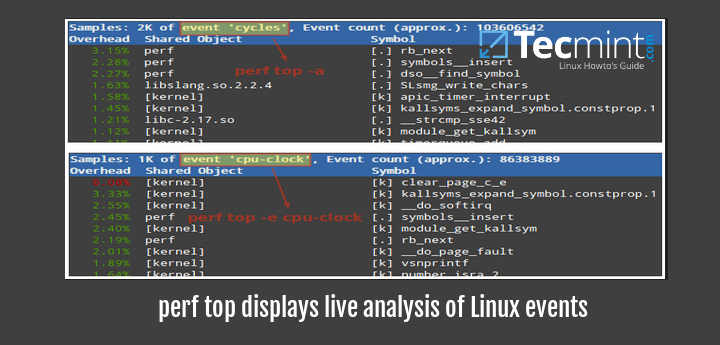
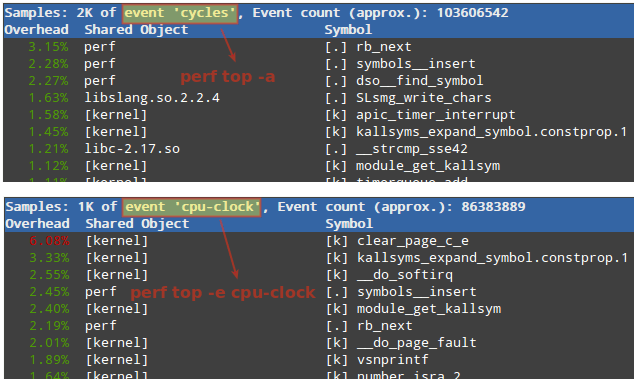
Perf top
perf top is similar to top command, in that it displays an almost real-time system profile (also known as live analysis).
With the
-a option you will display all of the known event types, whereas the -e option will allow you to choose a specific event category (as returned by perf list):
Will display all cycles event.
Will display all cpu-clock related events.
Live Analysis of Linux Performance
The first column in the output above represents the percentage of samples taken since the beginning of the run, grouped by function Symbol and Shared Object. More options are available in man perf-top.
Perf record
perf record runs a command and saves the statistical data into a file named perf.data inside the current working directory. It runs similarly to perf stat.
Type perf record followed by a command:
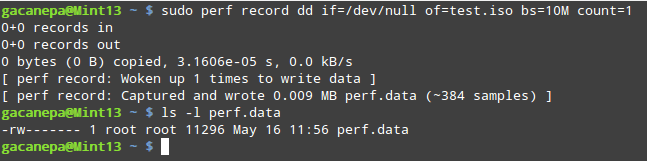
Record Command Statistical Data
Perf report
perf report formats the data collected in perf.data above into a performance report:
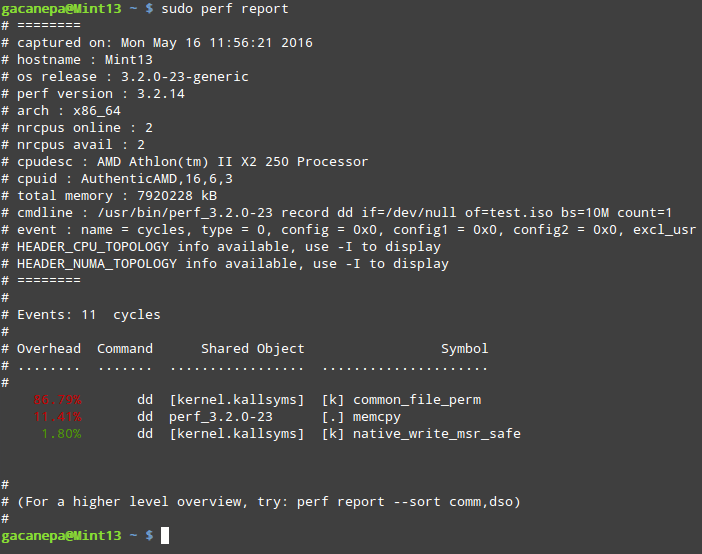
Perf Linux Performance Report
All of the above subcommands have a dedicated man page that can be invoked as:
where subcommand is either list, stat, top, record, or report. These are the most frequently used subcommands; others are listed in the documentation (refer to the Summary section for the link).
Summary
In this guide we have introduced you to perf, a performance monitoring and analysis tool for Linux. We highly encourage you to become familiar with its documentation which is maintained in https://perf.wiki.kernel.org.
If you find applications that are consuming a high percentage of resources, you may consider modifying the source code, or use other alternatives.
If you have questions about this article or suggestions to improve, we are all ears. Feel free to reach us using the comment form below.
Sign up here with your email



EmoticonEmoticon